Huggingface
LiteLLM supports the following types of Huggingface models:
- Text-generation-interface: Here's all the models that use this format.
- Conversational task: Here's all the models that use this format.
- Non TGI/Conversational-task LLMs
Usage
You need to tell LiteLLM when you're calling Huggingface.
This is done by adding the "huggingface/" prefix to model, example completion(model="huggingface/<model_name>",...).
- Text-generation-interface (TGI)
- Conversational-task (BlenderBot, etc.)
- Text Classification
- Text Generation (NOT TGI)
By default, LiteLLM will assume a huggingface call follows the TGI format.
- SDK
- PROXY
import os
from litellm import completion
# [OPTIONAL] set env var
os.environ["HUGGINGFACE_API_KEY"] = "huggingface_api_key"
messages = [{ "content": "There's a llama in my garden 😱 What should I do?","role": "user"}]
# e.g. Call 'WizardLM/WizardCoder-Python-34B-V1.0' hosted on HF Inference endpoints
response = completion(
model="huggingface/WizardLM/WizardCoder-Python-34B-V1.0",
messages=messages,
api_base="https://my-endpoint.huggingface.cloud"
)
print(response)
Add models to your config.yaml
model_list:
- model_name: wizard-coder
litellm_params:
model: huggingface/WizardLM/WizardCoder-Python-34B-V1.0
api_key: os.environ/HUGGINGFACE_API_KEY
api_base: "https://my-endpoint.endpoints.huggingface.cloud"
Start the proxy
$ litellm --config /path/to/config.yaml --debugTest it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "wizard-coder",
"messages": [
{
"role": "user",
"content": "I like you!"
}
],
}'
Append conversational to the model name
e.g. huggingface/conversational/<model-name>
- SDK
- PROXY
import os
from litellm import completion
# [OPTIONAL] set env var
os.environ["HUGGINGFACE_API_KEY"] = "huggingface_api_key"
messages = [{ "content": "There's a llama in my garden 😱 What should I do?","role": "user"}]
# e.g. Call 'facebook/blenderbot-400M-distill' hosted on HF Inference endpoints
response = completion(
model="huggingface/conversational/facebook/blenderbot-400M-distill",
messages=messages,
api_base="https://my-endpoint.huggingface.cloud"
)
print(response)
Add models to your config.yaml
model_list:
- model_name: blenderbot
litellm_params:
model: huggingface/conversational/facebook/blenderbot-400M-distill
api_key: os.environ/HUGGINGFACE_API_KEY
api_base: "https://my-endpoint.endpoints.huggingface.cloud"
Start the proxy
$ litellm --config /path/to/config.yaml --debugTest it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "blenderbot",
"messages": [
{
"role": "user",
"content": "I like you!"
}
],
}'
Append text-classification to the model name
e.g. huggingface/text-classification/<model-name>
- SDK
- PROXY
import os
from litellm import completion
# [OPTIONAL] set env var
os.environ["HUGGINGFACE_API_KEY"] = "huggingface_api_key"
messages = [{ "content": "I like you, I love you!","role": "user"}]
# e.g. Call 'shahrukhx01/question-vs-statement-classifier' hosted on HF Inference endpoints
response = completion(
model="huggingface/text-classification/shahrukhx01/question-vs-statement-classifier",
messages=messages,
api_base="https://my-endpoint.endpoints.huggingface.cloud",
)
print(response)
Add models to your config.yaml
model_list:
- model_name: bert-classifier
litellm_params:
model: huggingface/text-classification/shahrukhx01/question-vs-statement-classifier
api_key: os.environ/HUGGINGFACE_API_KEY
api_base: "https://my-endpoint.endpoints.huggingface.cloud"
Start the proxy
$ litellm --config /path/to/config.yaml --debugTest it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "bert-classifier",
"messages": [
{
"role": "user",
"content": "I like you!"
}
],
}'
Append text-generation to the model name
e.g. huggingface/text-generation/<model-name>
import os
from litellm import completion
# [OPTIONAL] set env var
os.environ["HUGGINGFACE_API_KEY"] = "huggingface_api_key"
messages = [{ "content": "There's a llama in my garden 😱 What should I do?","role": "user"}]
# e.g. Call 'roneneldan/TinyStories-3M' hosted on HF Inference endpoints
response = completion(
model="huggingface/text-generation/roneneldan/TinyStories-3M",
messages=messages,
api_base="https://p69xlsj6rpno5drq.us-east-1.aws.endpoints.huggingface.cloud",
)
print(response)
Streaming
You need to tell LiteLLM when you're calling Huggingface.
This is done by adding the "huggingface/" prefix to model, example completion(model="huggingface/<model_name>",...).
import os
from litellm import completion
# [OPTIONAL] set env var
os.environ["HUGGINGFACE_API_KEY"] = "huggingface_api_key"
messages = [{ "content": "There's a llama in my garden 😱 What should I do?","role": "user"}]
# e.g. Call 'facebook/blenderbot-400M-distill' hosted on HF Inference endpoints
response = completion(
model="huggingface/facebook/blenderbot-400M-distill",
messages=messages,
api_base="https://my-endpoint.huggingface.cloud",
stream=True
)
print(response)
for chunk in response:
print(chunk)
Embedding
LiteLLM supports Huggingface's text-embedding-inference format.
from litellm import embedding
import os
os.environ['HUGGINGFACE_API_KEY'] = ""
response = embedding(
model='huggingface/microsoft/codebert-base',
input=["good morning from litellm"]
)
Advanced
Setting API KEYS + API BASE
If required, you can set the api key + api base, set it in your os environment. Code for how it's sent
import os
os.environ["HUGGINGFACE_API_KEY"] = ""
os.environ["HUGGINGFACE_API_BASE"] = ""
Viewing Log probs
Using decoder_input_details - OpenAI echo
The echo param is supported by OpenAI Completions - Use litellm.text_completion() for this
from litellm import text_completion
response = text_completion(
model="huggingface/bigcode/starcoder",
prompt="good morning",
max_tokens=10, logprobs=10,
echo=True
)
Output
{
"id":"chatcmpl-3fc71792-c442-4ba1-a611-19dd0ac371ad",
"object":"text_completion",
"created":1698801125.936519,
"model":"bigcode/starcoder",
"choices":[
{
"text":", I'm going to make you a sand",
"index":0,
"logprobs":{
"tokens":[
"good",
" morning",
",",
" I",
"'m",
" going",
" to",
" make",
" you",
" a",
" s",
"and"
],
"token_logprobs":[
"None",
-14.96875,
-2.2285156,
-2.734375,
-2.0957031,
-2.0917969,
-0.09429932,
-3.1132812,
-1.3203125,
-1.2304688,
-1.6201172,
-0.010292053
]
},
"finish_reason":"length"
}
],
"usage":{
"completion_tokens":9,
"prompt_tokens":2,
"total_tokens":11
}
}
Models with Prompt Formatting
For models with special prompt templates (e.g. Llama2), we format the prompt to fit their template.
Models with natively Supported Prompt Templates
| Model Name | Works for Models | Function Call | Required OS Variables |
|---|---|---|---|
| mistralai/Mistral-7B-Instruct-v0.1 | mistralai/Mistral-7B-Instruct-v0.1 | completion(model='huggingface/mistralai/Mistral-7B-Instruct-v0.1', messages=messages, api_base="your_api_endpoint") | os.environ['HUGGINGFACE_API_KEY'] |
| meta-llama/Llama-2-7b-chat | All meta-llama llama2 chat models | completion(model='huggingface/meta-llama/Llama-2-7b', messages=messages, api_base="your_api_endpoint") | os.environ['HUGGINGFACE_API_KEY'] |
| tiiuae/falcon-7b-instruct | All falcon instruct models | completion(model='huggingface/tiiuae/falcon-7b-instruct', messages=messages, api_base="your_api_endpoint") | os.environ['HUGGINGFACE_API_KEY'] |
| mosaicml/mpt-7b-chat | All mpt chat models | completion(model='huggingface/mosaicml/mpt-7b-chat', messages=messages, api_base="your_api_endpoint") | os.environ['HUGGINGFACE_API_KEY'] |
| codellama/CodeLlama-34b-Instruct-hf | All codellama instruct models | completion(model='huggingface/codellama/CodeLlama-34b-Instruct-hf', messages=messages, api_base="your_api_endpoint") | os.environ['HUGGINGFACE_API_KEY'] |
| WizardLM/WizardCoder-Python-34B-V1.0 | All wizardcoder models | completion(model='huggingface/WizardLM/WizardCoder-Python-34B-V1.0', messages=messages, api_base="your_api_endpoint") | os.environ['HUGGINGFACE_API_KEY'] |
| Phind/Phind-CodeLlama-34B-v2 | All phind-codellama models | completion(model='huggingface/Phind/Phind-CodeLlama-34B-v2', messages=messages, api_base="your_api_endpoint") | os.environ['HUGGINGFACE_API_KEY'] |
What if we don't support a model you need? You can also specify you're own custom prompt formatting, in case we don't have your model covered yet.
Does this mean you have to specify a prompt for all models? No. By default we'll concatenate your message content to make a prompt.
Default Prompt Template
def default_pt(messages):
return " ".join(message["content"] for message in messages)
Code for how prompt formats work in LiteLLM
Custom prompt templates
# Create your own custom prompt template works
litellm.register_prompt_template(
model="togethercomputer/LLaMA-2-7B-32K",
roles={
"system": {
"pre_message": "[INST] <<SYS>>\n",
"post_message": "\n<</SYS>>\n [/INST]\n"
},
"user": {
"pre_message": "[INST] ",
"post_message": " [/INST]\n"
},
"assistant": {
"post_message": "\n"
}
}
)
def test_huggingface_custom_model():
model = "huggingface/togethercomputer/LLaMA-2-7B-32K"
response = completion(model=model, messages=messages, api_base="https://ecd4sb5n09bo4ei2.us-east-1.aws.endpoints.huggingface.cloud")
print(response['choices'][0]['message']['content'])
return response
test_huggingface_custom_model()
Deploying a model on huggingface
You can use any chat/text model from Hugging Face with the following steps:
- Copy your model id/url from Huggingface Inference Endpoints
- Go to https://ui.endpoints.huggingface.co/
- Copy the url of the specific model you'd like to use
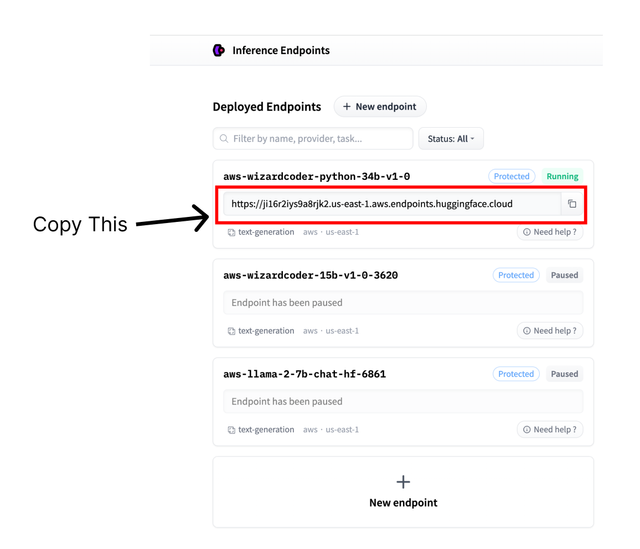
- Set it as your model name
- Set your HUGGINGFACE_API_KEY as an environment variable
Need help deploying a model on huggingface? Check out this guide.
output
Same as the OpenAI format, but also includes logprobs. See the code
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "\ud83d\ude31\n\nComment: @SarahSzabo I'm",
"role": "assistant",
"logprobs": -22.697942825499993
}
}
],
"created": 1693436637.38206,
"model": "https://ji16r2iys9a8rjk2.us-east-1.aws.endpoints.huggingface.cloud",
"usage": {
"prompt_tokens": 14,
"completion_tokens": 11,
"total_tokens": 25
}
}
FAQ
Does this support stop sequences?
Yes, we support stop sequences - and you can pass as many as allowed by Huggingface (or any provider!)
How do you deal with repetition penalty?
We map the presence penalty parameter in openai to the repetition penalty parameter on Huggingface. See code.
We welcome any suggestions for improving our Huggingface integration - Create an issue/Join the Discord!